MODEL-ENSEMBLE TRUST-REGION POLICY OPTIMIZATIONICLR 2018 paper from Thanard Kurutach, Ignashi Clavera, Yan Duan, Aviv Tamar, Pieter AbbeelJan 18, 2021Jan 18, 2021
DDQN, Prioritized Replay, and Dueling DQNDDQN — Double Deep Q-network, (Hasselt et al, AAAI 2016)Apr 30, 2020Apr 30, 2020
Double Q-Learning and Value overestimation in Q-LearningThe problem is named maximization bias problem.Apr 30, 2020Apr 30, 2020
Journey to an 2020 summer internshipIn my PhD career, the first year for prelim, and the second year for Qual. In my third year EE PhD career, having an internship might be…Apr 26, 2020Apr 26, 2020
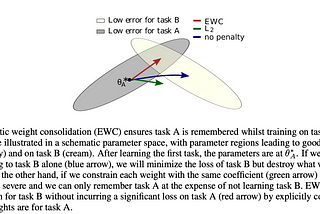
EWC:Elastic Weight ConsolidationPaper: “Overcoming catastrophic forgetting in neural networks”.Apr 25, 2020Apr 25, 2020
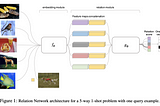
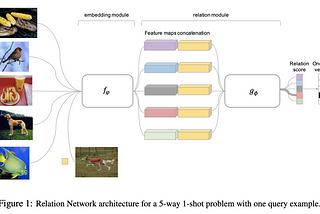
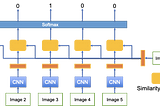
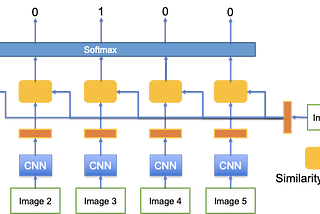
Learning to Compare: Relation Network for Few-Shot Learning這篇文章稱之為Relation Network,主要要解決few-shot learning中similairty function的問題,其架構可以自己最佳化出最好的similarity function.類似的文章可以參考Prototypical NetworkApr 24, 2020Apr 24, 2020
AWS: Jupyter notebook登入 (Log in AWS with Jupyter and Tensorboard port liked) You can create a shell script to execute the command below. Please replace…Apr 24, 2020Apr 24, 2020
Literature Review: Implementation matters in deep policy gradients: a case study on PPO and TRPO這是一篇ICLR 2019 Oral paper,來自於MIT Logan Engstrom.Apr 22, 2020Apr 22, 2020
Useful Tips in Medium EditingNo words. Just give you frequent useful tips as reference.Apr 22, 2020Apr 22, 2020